| Japanese | English |
当時の日本語音声の測定で、研究結果として、日本語の音声の発音は、測定結果として、少なくとも二つの周波数が組み合わさって出来ていることがわかりました。またそのうちのひとつは、基本周波数と呼ばれるもので、男性は150Hzくらい、女性は250Hzから300Hzくらいノが確かめられ、文献によると子供はさらに高い周波数、さらに想像ですが赤ちゃんはさらに高い周波数と考えられました。これはのど仏の周波数で、のど仏と、声帯を構成する、のどの管の物理的な特性、太さ、長さによるものでした。これは声を分析すると、その生体的な特徴が計算から求められることを意味しました。
またもうひとつは、フォルマント周波数と呼ばれるものです。これは発音するときに、口や、舌を使い、音の高さを作るものです。この音の高さが基本周波数とは別に存在しました。
ただ、当時のDSSF3は日本語音声の分析には、ACFと連携するような高解像度なオクターブバンド分析機能がなく、ランニングACF分析のレコーダーからの再生ををスペクトラムアナライザーを使用して分析し、スペクトラムを確認した後に、ACFの波形から、τ1ピッチ(音の高さ)、を読み取り、フォルマントの分析を行いました。これは手間がかかる上、時定数も適当ではなく、発音の中での適当な場所をFFT分析するために、再現性に乏しく、研究としての正確性に書けるため、ランニングACF分析と、連携した、FFT分析が望まれました。
2003/07/01
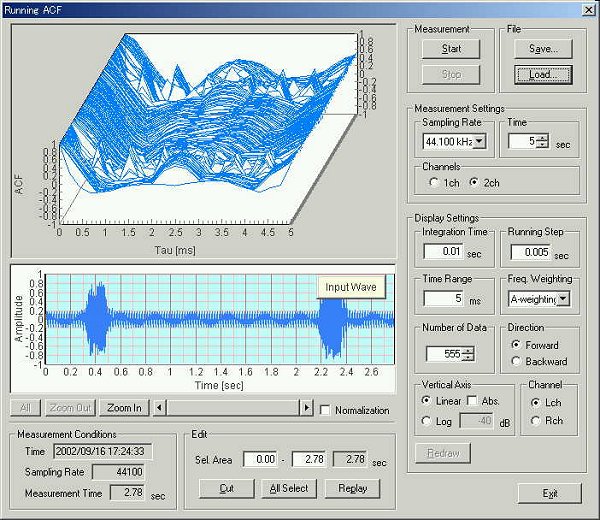
▼ランニングACF解析結果表示 [SA]
分析結果のグラフは指定したポイントに赤丸が表示されます。他のパラメータやACFに切り替えても、赤丸のポイントと、分析データのテーブル表が扱いやすいように改良しました。
▼ランニングACF 音の時間波形とスペクトル [SA]
分析結果のグラフ表示に音の時間波形とスペクトルを追加したことによって解析しやすくなりました。
従来技術のFFT分析をACF分析と、同時同レベルで、分析できるようになり、研究が簡単になりました。
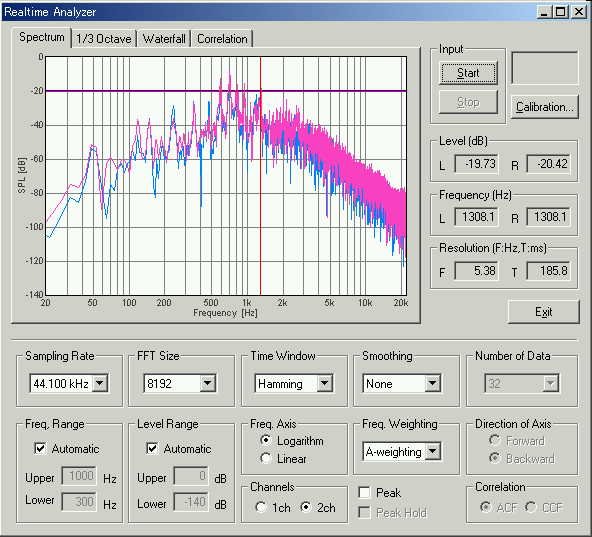
・ FFTアナライザーに 1/6, 1/12, 1/24 オクターブ分析を追加RA]
RA(リアルタイムアナライザー)において、FFT分析結果のリアルタイム表示の機能強化として、オクターブバンドで1/1, 1/3, 1/6, 1/12,
1/24 をプルダウンメニューから選択できるようになりました。また100Hz,1kHz,10kHzの位置を灰色の帯で表示するようにしました。
・ リアルタイムアナライザーのSpectrogram表示を追加 RA]
RA(リアルタイムアナライザー)において、FFT分析結果のリアルタイム表示の機能強化として、周波数別の音圧レベルの長時間の時間測定を行うために、従来の3次元表示のWaterFall
表示とは別に、レインボーカラーと、グレーカラー表示が選択できるスペクトグラム表示機能が加わりました。
当時のデータを今の技術で、分析してみることにしました。
以下に加筆しています。
声帯の基本周波数と、声道のフォルマント周波数をランニングACF分析で調べてみました
| 計測日時 | 2002年9月16日 17:00、 2004年7月15日 |
| 計測場所 | 愛知県名古屋市 |
| マイク | SONY ECM-MS957 |
| パソコン | DELL INSPIRON 7500 |
| OS | Windows 2000 Professional |
| 測定分析ソフト | DSSF3 DSSFバージョン5.0.5.6 DEV |
| WAVE sound file: |
以下は次の加筆分までは、以前発表のものです。
ランニングACF分析の様子。「あ」と2回発声しました。
パワースペクトラム表示
パワースペクトラムから眺めたところでは、ピーク周波数は48.4 Hz、118.4 Hz、150.7 Hz、236.9 Hz、355.3 Hz、484.5 Hz、597.5 Hz、650 Hz、716 Hz、834.4 Hz、958 Hz、1259.7 Hz、2799.3 Hz、3149.2 Hzなどです。
ACFから眺めてみると、ACFの場合は山のピークのX軸を読みます。遅れ時間です。遅れ時間がmsec単位の場合、1000をこの遅れ時間で割ると周波数成分が出ます。これはパワースペクトラムのピークと同じ意味を持ちます。
このACFのグラフは音響信号を10 msecの積分時間で、ランニングステップ5msecで分析したもので、上のパワースペクトラムによく対応しているものをあげてみました。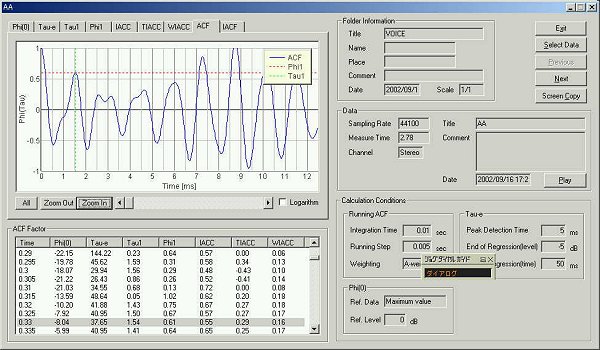
図で一番のピーク周波数は8.75 msecです。1000/8.75=114.3 Hz これは基本周波数ですから、一番低い基本周波数は114.3 Hzです。これは声帯の振動数です。
114.3 Hz 基本周波数図の中で最初のピーク周波数は1.54 msecです。1000/1.54=649 Hzです。これはフォルマント周波数とよばれるものです。耳に聞える音の高さになります。
649 Hz フォルマント周波数 (共鳴周波数)音声学の本には、喉の声帯の振動数は、母音の場合はほぼ一定とあります。この場合、114.3 Hz(基本周波数)でした。話者によって異なり、話し方でも若干変化するそうです。
喉から口までの舌を含む管がフォルマント(共鳴周波数)音の高さを決定し「あ」や「い」などの母音の音色を決定します。この場合649 Hzでした。音速34000cm/secを649 Hzで割ると52cmです。これは声道の4倍ですから、声道の長さは13cmになります。舌の置き方で変わりますが、話者が同じならば一定だそうです。SAで分析します。
計算条件です。音声の分析は母音は100 msecの積分時間で、ランニングステップ50
msecずつでおこないます。
分析結果です。
▼ 発声50 msec後のACF 基本周波数9 msec
▼ 発声100 msec後のACF 基本周波数9 msec
▼ 発声150 msec後のACF 基本周波数9 msec
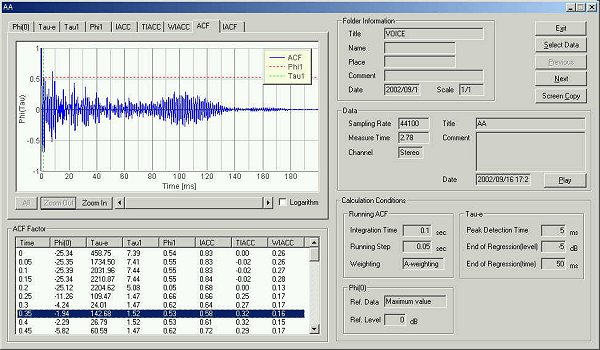
▼ 発声200 msec後のACF 基本周波数 9 msec
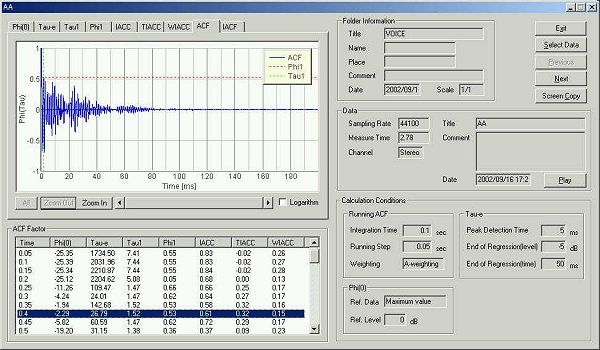
▼ 発声250 msec後のACF 基本周波数 9 msec
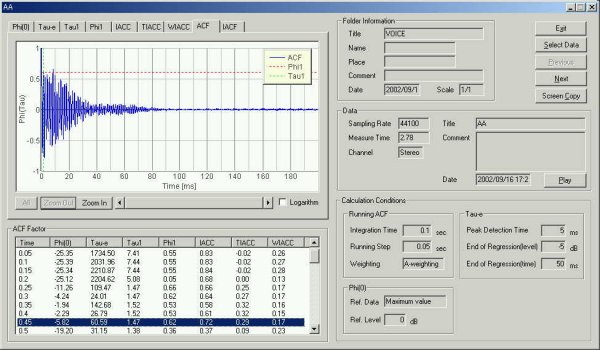
▼ 発声300 msec後のACF 基本周波数 13 msec
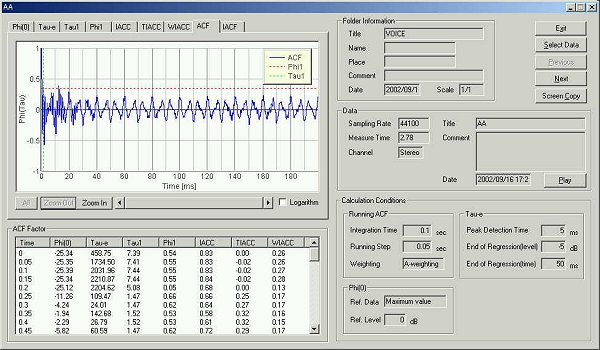
今度は計算条件を変えてみます。10 msecの積分時間で、ランニングステップ 5 msecで行ないます。
分析結果です。
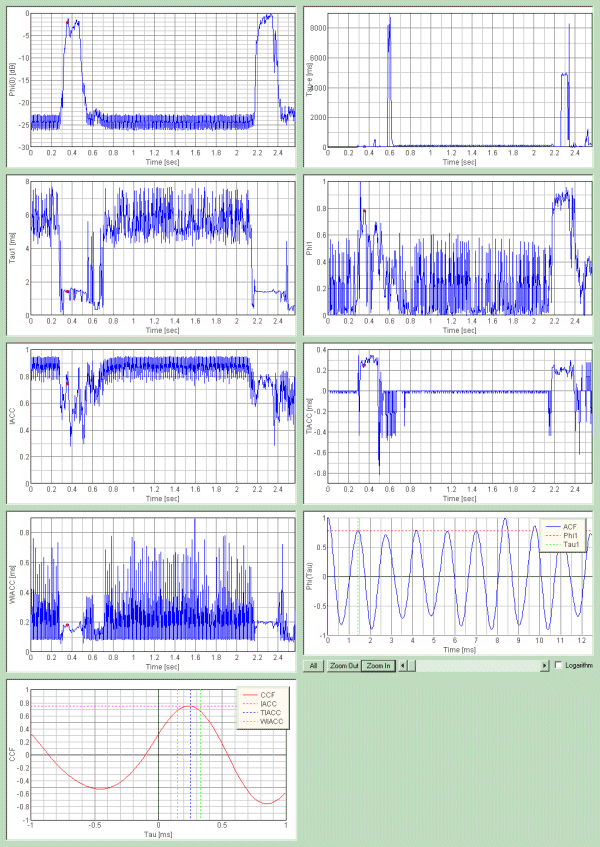
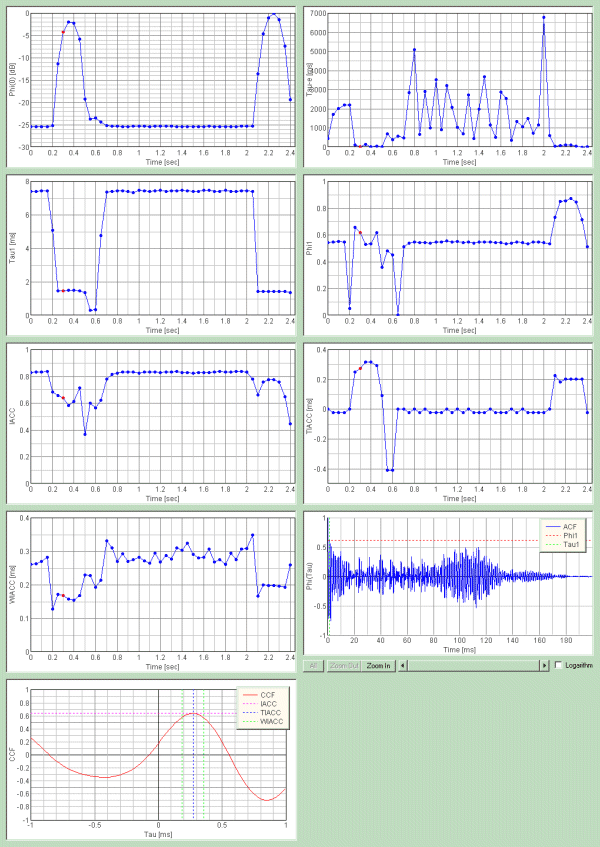
50msecづつの分析を行いましたが、問題は音圧レベルの時間変化が、まず「あ」という発音に固有のものがあります。Φ(0)の時間経過のグラフ最初のグラフです。これが最も重要です。積分時間100msecランニングステップ50msecのこのレベルでも、単音の識別程度であれば十分ですが、もっと精密さが必要であれば、たとえば1msec単位の時間経過グラフであればもっと精密分析するのに役立つでしょう。このグラフで紛らわしければ、τeなどの響き成分や、τ1等のフォルマント周波数の音の高さで、さらに正確な音声認識を行うことができます。先ほどの精密分析や、声帯の基本周波数などから話者の喉の長さや、声帯の振動数まで知ることができれば、話者の性別や、話者識別も可能です。とくにACFのグラフから得られるピッチやピッチの強さなどの情報やτeなどの響き成分からは、発声にかかわる生体的な動作や状態などの情報も含まれていると考えられます。 April 2003 by Masatsugu Sakurai
2004年 7月加筆。
SAで、データを再計算します。計算条件は同じです。積分時間や、ランニングステップは母音、”あ”としては音声認識としては適当とされている数値です。
SAでの分析結果です。これはWAVEつまり音の振幅の時間表示グラフです。測定データは2.01秒間です。積分時間が0.1秒ですから表は最後の0.1秒をはずした2秒の表示です。つまり、2秒から0.1秒間平均した、分析結果が2秒のところに表示されます。
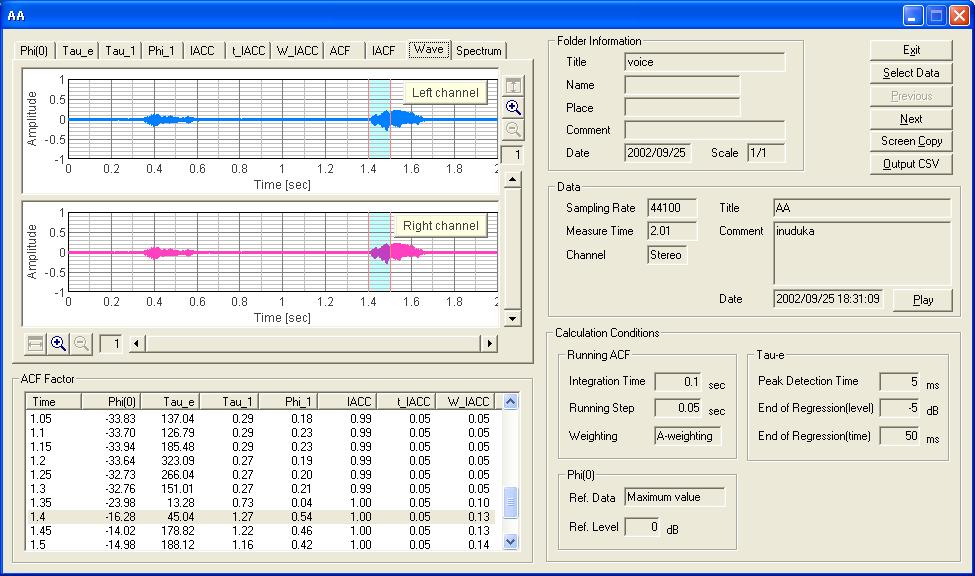
下は、同じ画像ですが、X軸の時間を16倍に拡大してあります。この拡大は、まだまだ出来ます、この上に32倍もあります。この倍率も、2002年には不足していました。当時は分析時間解像度を1/1000とか1/10000とかに持っていくとは考えていませんでした。現在は一部、1/100000、1/1000000が要求されてきています。(2CHの遅延時間からの位置情報の計算など)
このWAVE表示では、音を再生して聴く事も出来ます。この分析結果のすべてをテキストデータとして出力もできます。(かなり膨大な量です。)このWAVE表示で、FFT分析したいところをX軸上で、クリックして、指定します。下の図のように1.4秒のところに青い色の区間が現れます。この区間はやはり、0.1秒つまりFFT分析するための平均時間です。つまりここで指定した、この時間の間をスペクトラムアナライザーで分析した、周波数応答のグラフがスペクトラムの画面に計算出力されます。
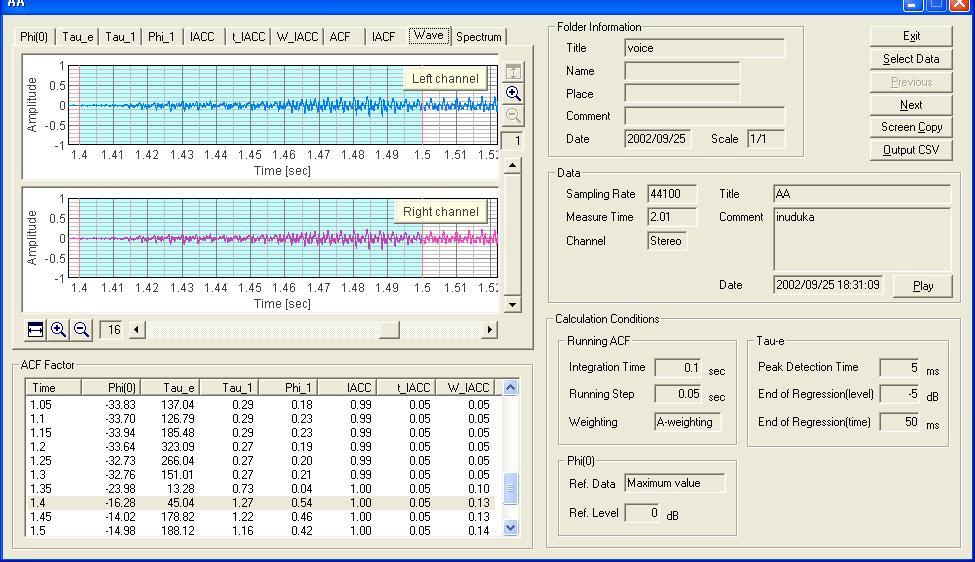
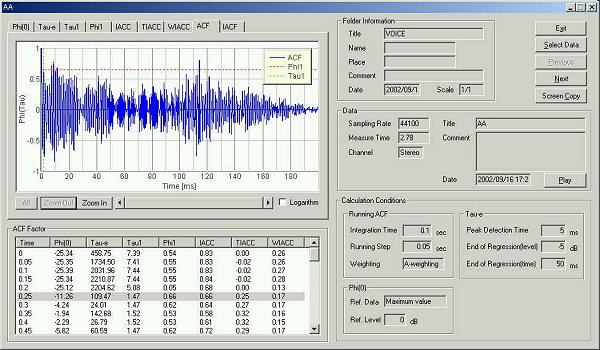
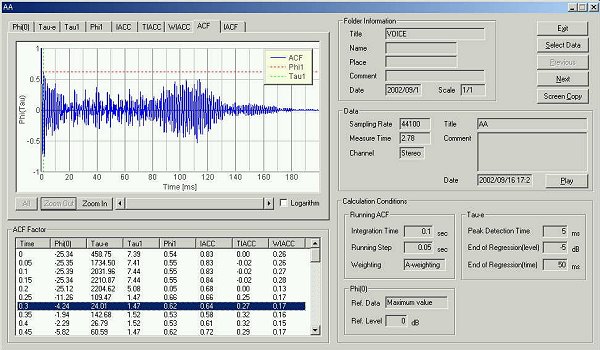
SAでのスペクトラム表示。これは母音”あ”の発生開始100msecのFFT分析結果です。今までこういう分析は出来ませんでした。またこれはACFでの分析結果としてのΦ(0)のグラフなどでも、どれで指定しても、どの点を指定しても、表示をその対応する点のスペクトラム表示に切り替えることができます。またこの分析は、ACF分析の、積分時間がFFT分析の時定数と、マッチさせてあり。ACFと、FFTの計算結果からすぐに対応付けた分析できる点が効果的でした。
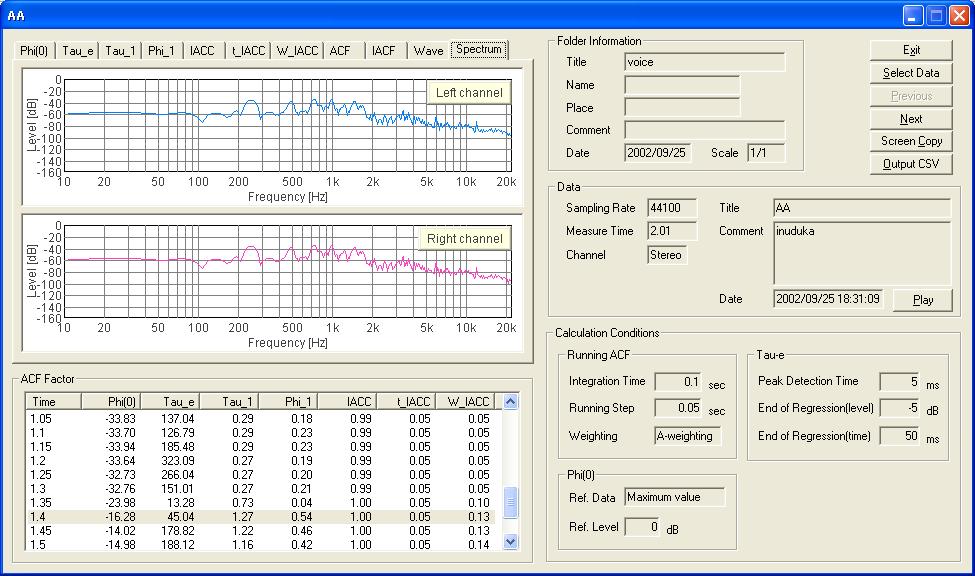
このスペクトラム分析から、この女性の基本周波数は 約250Hzであることがわかります。フォルマントはおおよそ、750Hzにあり1KHzに第2フォルマントが
この”あ”の発声が、2音源のシンセサイザーがあれば”あ”の発音が似せて作れるほどに、正確に音圧レベルも求められます。この分析では、もちろん100msecの時定数での分析ですから、、似せて作った音も、同じ100msecの分析を行うと、同じ結果が得られるはずです。
ここでは”あ”の発音です。注意してもらいたいのは、実際は美しく発音された、”あ”の音は、母音の意味だけではなく、もっと、たくさんの情報を持っています。そのたくさんの情報は、時定数100msecの中では、うずもれてしまいます。
それはこのスペクトラムを似せて作った、シンセサイザーの音が聴くことが出来れば、すぐわかると思います。
さて、いよいよ、今までのτ1のグラフです。この場合、τ1はフォルマント周波数です。この図の赤い点で、画像の下のテーブルで時間1.4秒はτ1が1.27です。1000を1.27で割ると。787.4HZです。発音者は口や舌を動かして、基本周波数を響かせて、この高さのフォルマント周波数をこういう風に時間変化させれば、こういう声が聞こえるのだなと読み取ります。
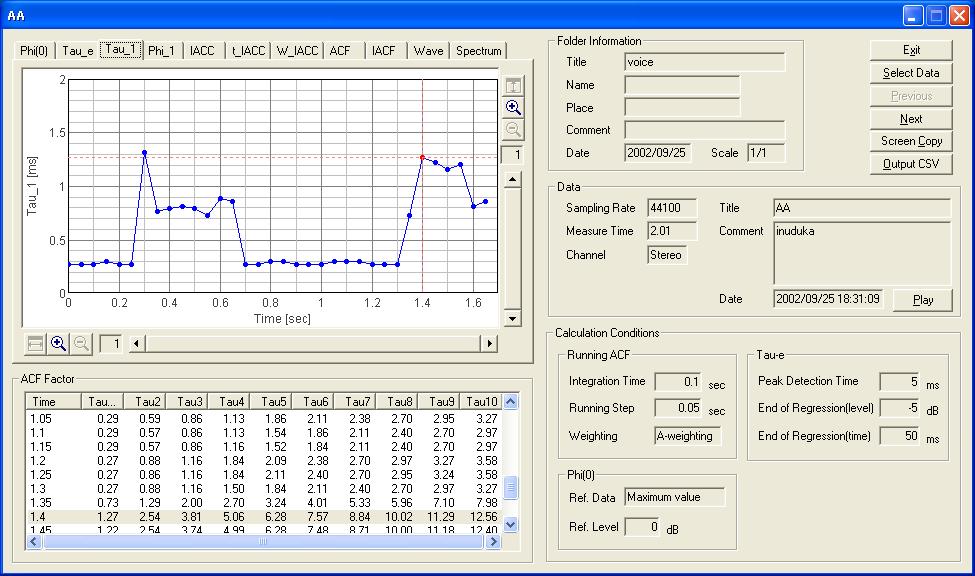
これを聴くと聞く人は、日本語の”あ”があらかじめ解っていれば、”あ”かも知れない、いや絶対”あ”だと認識できるのだなとわかります。この図はτ1の時間変化のグラフです。
これは。1.4秒のACFのグラフです。人間の脳にはこの波形が送られて、脳はτ1の時間的変化のみで、”あ”の音声認識を行うかどうかは、いえませんが。
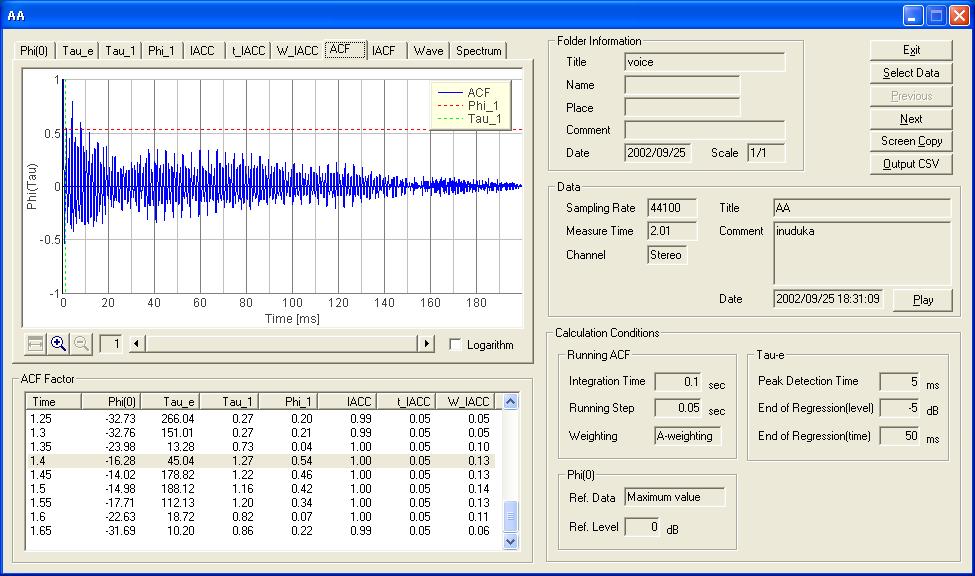
以後続く音声の分析で、もっとわかると思います。
2004年7月加筆分終了
2005年4月10日加筆開始。
最初の男性の声 voice1.wav 、をレコーダーに読みこんでみます。読み込み方は航空機騒音の1の測定を参考にしてください。この場合(一般的にLINKを右クリックして、名前をつけて保存を選択します。そして格納場所をマイミュージックにして、名前はそのまま表示のまま保存を選択すれば、ダウンロードできます。そのダウンロードしたWAVEファイルをレコーダーで、読み込み(ロード)します。
レコーダーの説明としては、今このレコーダーは測定システムで、再生用として設定されています。この場合、FFT分析やオシロスコープなどの機能でスタートボタンをマウスクリックして測定開始すると、レコーダーが自動プレイされます。そしてプレイが終了すると測定は自動的に終了します。
また記録の優先は、入力データを記録するか、出力データを記録するかです。これはシグナルジェネレーターなどの出力データを記録と、マイクなどからの入力データを記録するかの選択をするものです。この機能を利用すると、たとえば、パルスを出力して、そのデータをマイク入力して、レコーダーで自動記録すれば、遅れ時間から、スピーカーとマイクなどの距離が測定できたり、応答波形の計測が可能です。
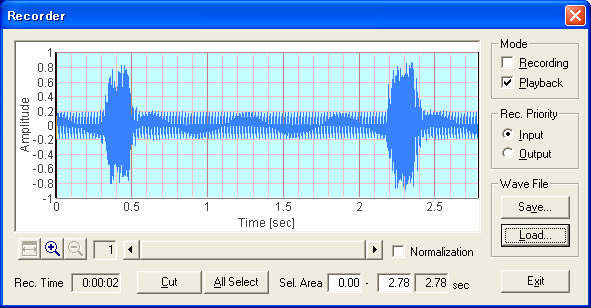
レコーダーに読み込んだ男性の”あ”の発声をスペクトグラムで測定してみます。
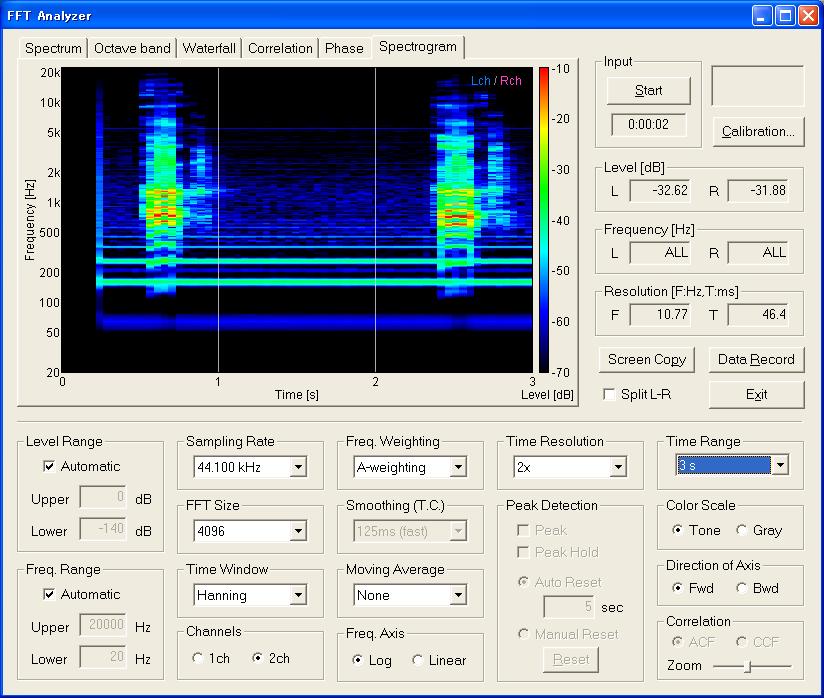
最初の部分が黒いのは、測定画面で、X軸方向を3秒で、レコーダーのWAVEデータの時間が2.8秒だからです。
スペクトグラム測定の開始ボタンのクリックで、再生準備されているレコーダー(この場合はプレーヤー)と連動して、自動測定されたためです。もちろん再生終了とともに測定も自動終了します。この場合、WAVEデータをレコーダーで録音するのも再生するのも、スペクトグラム測定も、オールデジタルのWAVEデータのまま行いますから、データの劣化はありません。ですから、DSSF3を使用して、このWAVEファイルを分析すれば、誰でも同じ結果が得られます。
このスペクトグラムの測定画像で、2回の発音は2番目のほうが低い周波数で発音されています、これだけではなんともいえませんが、確かに発音の感じとこの画像表示は共通性があります。
発声時間が短いために、時間軸方向を拡大して表示させるようにスペクトグラム測定を表示を1秒にして行ってみます。この場合は最初の1.8秒は測定中に消えて最後の1秒のみが測定表示されました。
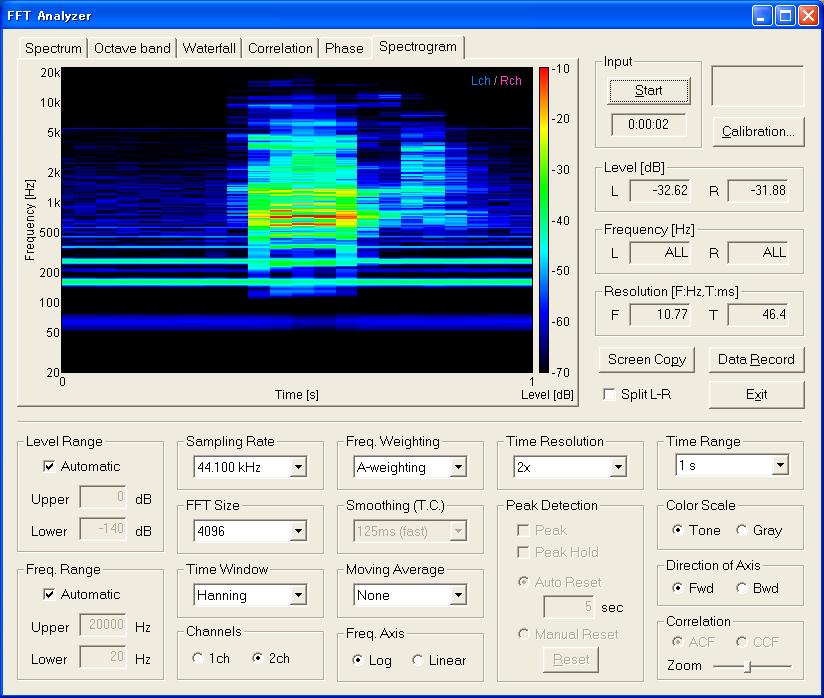
第1フォルマントは共鳴周波数のなかでは一番低い周波数ですから一番下の赤い部分、第2フォルマントは2番目の赤い線の部分、一番下の青色の部分の真ん中に薄い細い緑色は110HZくらいで、基本周波数のはずです。基本周波数は低い周波数ですから、エネルギー的には大きいのです。それでも基本周波数はよく聞こえないものです。そのわけは人間の場合、聴覚の特性で、聞こえなくしてあるからです。その反対に、フォルマントなどの必要な周波数帯域はよく聞こえます。またこの今回の発声とおなじようにスペクトグラムの分析からの音声認識の場合は、パターンが変化するため、同定しようとすると、データベースと比較して一番近いものを探します。この分析方法は、扱うデータも多く複雑です。ACF分析で同様に行うとすると、最初のピークτ1から順に基本周波数までのピークを山の遅れ時間と高さなどの数値を使用して行います。
とはいえ、スペクトグラム測定を利用して、発声などの音響分析は可能です。またスペクトグラムを残しておけば、手軽にすぐ判別できます。同じように発声されているかどうかは充分チェックできます。また音声だけでなく、挨拶、受け答えなど話し方への応用はもちろん可能ですし、ものまね、楽器などの演奏の練習、外国語の学習などにも利用できます。
2005年4月10日加筆終了
April 2003 by Masatsugu Sakurai